在收集資料的時候,要注意類別的選擇。
對於數值型(numerical)資料就要請大家注意有序型(ordinal)與類別型(nominal)的差別。
所謂ordinal隱含著順序(order),可以看做是符合三一律的數,又可以分為連續型(continuous)或是離散型(discrete)。
連續型變數可以有效讓使用者看出離散程度差異與待預測的對象之關聯。
離散型變數仍保有序列差異的特性,但是容易出現資料間的斷層,解讀開始出現困難。
而nominal本義為名義上的,代表其意義更接近dummy,可用來告訴使用者兩者或不同類別之間不同,要如何說明不同,就不在說明的範圍了。
舉例來說:
編碼的功用,可以想成用來將不適合用來當成特徵的nominal變數轉換成有意義的有序型變數。
以常用的框架來說,one-hot encoding/embedding是常用的編碼模式。
大部分都有一個特點,就是維度擴增。
利用更高維度的表示法,來說明不同觀測資料的關係。
可以比較一下支援向量機(Support Vector Machine, SVM)
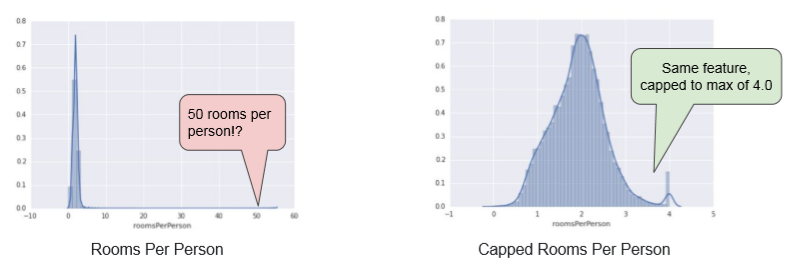
這是課程中解釋的一張圖,說明統計與機器學習對於資料判讀的差異特性。
我想,重點就在資料數量的多寡吧。


 iThome鐵人賽
iThome鐵人賽